AI RFP Analysis: From a 150-Page RFP to Scored Requirements in Hours
The familiar scene
A 150-page RFP lands on a Friday afternoon. Somewhere inside it are 200+ discrete requirements, a third of them ambiguous, a handful of them deal-breakers. The traditional next step: days of senior engineering time spent reading, highlighting, and building a spreadsheet — before a single strategic decision gets made.
RFP analysis is not RFP response. Response tools help you write faster once you've decided to bid. Analysis is everything that should happen first: what is actually being asked, can we meet it, where are we exposed, and is this deal worth pursuing at all. That's the part AI changes most.
How AI RFP analysis works
A modern analysis pipeline runs in four stages, each one producing an artifact a human can inspect and override:
1. Requirement extraction
Every "shall," "must," and buried table row becomes a discrete, numbered requirement — including the ones hidden in appendices.
2. Capability matching
Each requirement is matched against your product knowledge base — documentation, past proposals, certified configurations — not a generic model's guesswork.
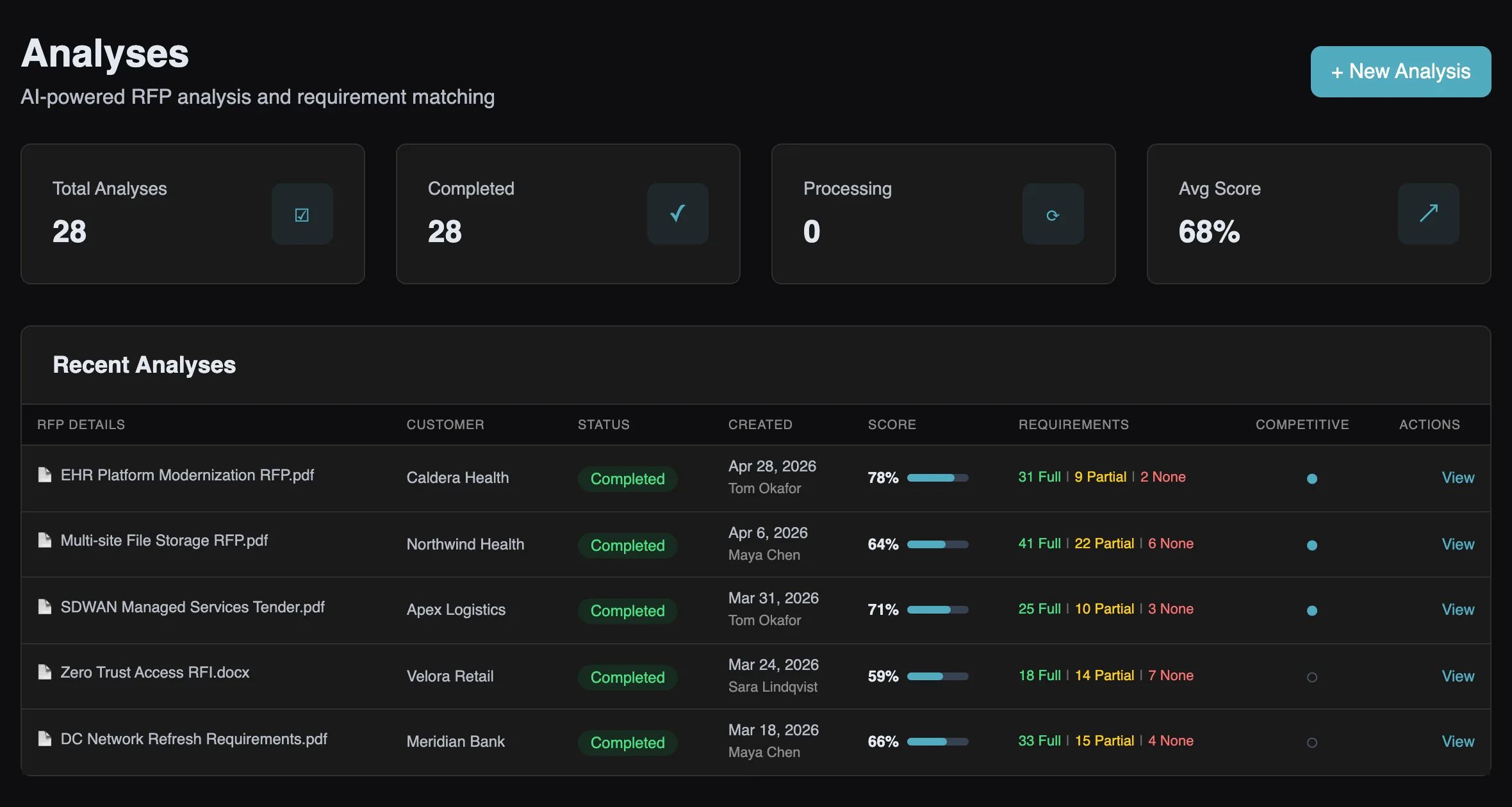
3. Full / Partial / Gap scoring
Every requirement lands in one of three buckets, with evidence attached. The aggregate becomes your match score for the whole RFP.
4. Positioning recommendations
Where you're strong, lead. Where you're partial, frame. Where you're exposed, decide consciously — concede, mitigate, or no-bid.
Why the score matters more than the draft
A "30 Full | 40 Partial | 13 Gap" breakdown is worth more than a fast first draft, because it changes decisions that happen before writing:
- Bid/no-bid gets honest. A 56% match score on a deal with eight competitors is a different conversation than a 78% score against two. (See our 5-minute qualification checklist.)
- SME time goes where it counts. Your specialists answer the 13 gaps and the ambiguous partials — not the 30 requirements the knowledge base already answers verbatim.
- Exposure is known, not discovered. The worst place to learn about a gap is the evaluation call. The analysis surfaces it on day one, with time to mitigate.
- Every answer is defensible. Matches cite the underlying source — a spec page, a certified configuration, a past proposal — so reviewers verify instead of re-research.
What stays human
Analysis tooling does not decide your win themes, doesn't know that the CIO is an ex-customer of your competitor, and can't judge whether a "partial" is strategically fine or fatal for this particular buyer. Those calls belong to the deal team. The honest division of labor: AI does the reading, extraction, matching, and first-pass scoring; humans do judgment, strategy, and the conversations that actually win the technical evaluation.
The practical payoff
The work that used to consume days of senior time before any decision could be made now takes hours — and the decision itself gets made with requirement-level evidence instead of a skim and a hunch.
Related reading
Analyze your next RFP before anyone starts writing
Upload a real RFP in your pilot workspace and see requirement-level scoring on your own product data.
Request a Demo